
专题:DeepSeek为何能滚动全球AI圈开云(中国)Kaiyun·官方网站 - 登录入口
国产AI大模子范畴,相称打扰!
1月20日下昼,总理主捏召开大家、企业家和教科文卫体等范畴代表谈话会。

此前,相称少出头的DeepSeek雇主梁文锋,受邀进入并发言。

中国AI界的外传大佬,真东谈主比思象中还年青啊,皮肤珍贵好,看着还以为是学生代表。
这是见证历史性一刻,AI大佬上新闻联播了。
在进入总理睬议的并吞天,DeepSeek在官微上,发布了DeepSeek-R1 发布,性能对标 OpenAI o1 郑再版。

DeepSeek-R1 在后查察阶段大范畴使用了强化学习技能,在仅有一丝标注数据的情况下,极大普及了模子推理才气。
在数学、代码、当然话语推理等任务上,性能并排 OpenAI o1 郑再版。

R1的32B和70B版块,性能远远率先了OpenAI的GPT-4o,并靠拢 o1-mini。

现时,DeepSeek一经全面上线了 R1,群众不错径直体验。

好意思国建筑诡计干事室 Workshop-APD 的独创东谈主Matthew Berman 默示:DeepSeek R1 领有我所见过的最像东谈主类的内心独白。
现时土产货运行的 14b DeepSeek R1 蒸馏模子,能够把问题回话成这样,咱还要啥自行车呢?


17岁考入浙大
30岁创办幻方
如斯蛮横的DeepSeek大模子,背后并是不什么互联网科技大厂,而是炒股的。

DeepSeek深度求索,来自金融范畴的头部量化:幻方量化。

梁文锋是幻方量化的骨子截至东谈主,他在DeepSeek最终受益的股份比例超80%。
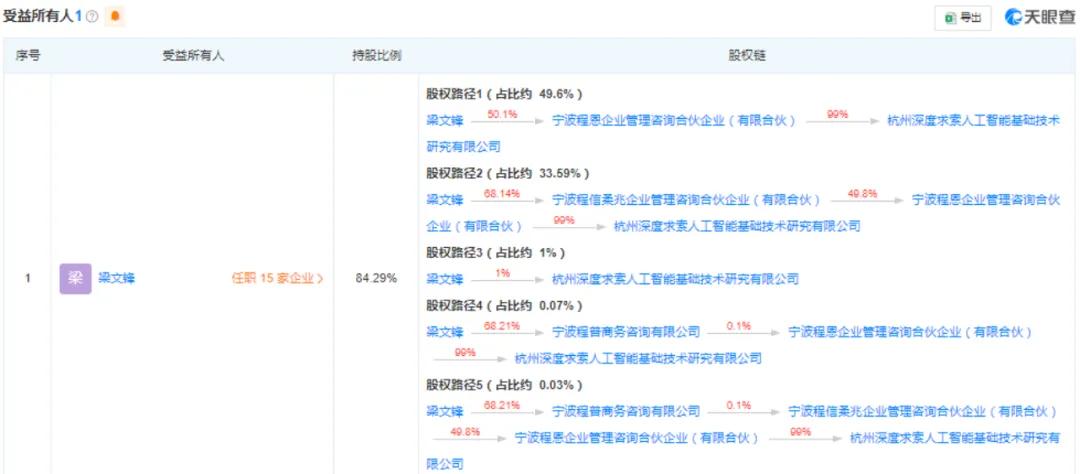
1985年,梁文锋出身于广东湛江,那处盛产生蚝。他本硕就读于浙江大学,攻读东谈主工智能,年青念书时就确定“AI定会改变宇宙”。
2008年,在浙大念书期间,23岁的梁文锋与同学整个组团队运转累积市集行情数据、金融市集其他关总共据以及宏不雅经济等数据。
梁文锋运转使用机器学习等技能,探索量化往返。
他的硕士毕业论文题目是《基于低老本PTZ录像机的决策追踪算法参谋》。

梁文锋默示:我方是八十年代在广东一个五线城市长大的。
我的父亲是小学敦厚,九十年代,广东收成契机好多,那时有不少家长到我家里来,基本即是家长合计念书没用。
但现时且归看,不雅念齐变了。因为钱不好赚了,连开出租车的契机可能齐没了。一代东谈主的时分就变了。
毕业后,梁文锋没去作念才略员,而是下场作念量化投资,成立幻方量化。
他主导的幻方量化在2016岁首度上线AI战术,并于2017年收尾投资战术全面AI化,成为量化投资范畴的转变前锋。
幻方量化成立仅6年处治范畴即曾达到千亿,被称为‘量化四大天王’之一。

亦然国内唯独公开声称有领有万张英伟达A100显卡的企业,其算力储备量就算是在一众互联网公司科技公司里,也豪不失色。
2023年,梁文锋创立了深度求索(DeepSeek)。

有讯息称,DeepSeek团队不招聘高等技能专科东谈主员。
职工的干事年限约为3到5年,而那些领有8年以上研发教化的东谈主还可能会被径直拒却。因为他们发怵这样的东谈主职守太重、缺乏转变的能源。
梁文锋曾对36氪暗涌说:
“淌若追求短期决策,找现成有教化的东谈主是对的。但淌若看永久,教化就没那么繁重,基础才气、创造性、嗜好等更繁重。”
就像群众不行能猜到,作念游戏显卡的英伟达,临了会成为AI界最繁重的公司。
群众也不行能猜到,中国AI大模子的但愿,可能就在炒股的公司身上。
背靠幻方量化的DeepSeek还不差钱。
梁文锋在2024年默示,短期内莫得融资谈论,濒临的问题从来不是钱,而是高端芯片被禁运。
不参与融资,也很少对外发声,闷声去作念AI。
外界齐合计DeepSeek很玄机。
近期“雷军千万年薪挖95后天才AI青娥”的热点话题也转折地与梁文锋相关,因为雷军尝试挖走的这位90后青娥罗福莉,此前恰是梁文锋旗下深度求索(DeepSeek)团队的研发成员。
2024年12月26日,DeepSeek发布了DeepSeek-V3,况且还公开了由梁文锋、罗福莉等东谈主撰写的53页论文《DeepSeek-V3 Technical Report》。


AI界拼多多
此前DeepSeek一直被冠以“AI界拼多多”。
它开启了中国大模子价钱战。
2024年5月,DeepSeek发布的一款名为DeepSeek V2的开源模子,提供了史无先例的性价比:
推理老本被降到每百万token仅 1块钱,在那时约等于Llama3 70B的七分之一,GPT-4 Turbo的七十分之一。
随后,字节、腾讯、百度、阿里、kimi等AI公司侍从降价。
梁文锋默示,我方不是特意成为一条鲶鱼,仅仅不留心成了一条鲶鱼。没思到价钱让群众这样明锐。仅仅按照我方的步调来作念事,然后核算老本订价。
此次新发布的DeepSeek-R1 API 价钱,同样过劲。
DeepSeek-R1 API订价为:每百万输入 tokens 1 元(缓存掷中)/ 4 元(缓存未掷中),每百万输出 tokens 16 元。

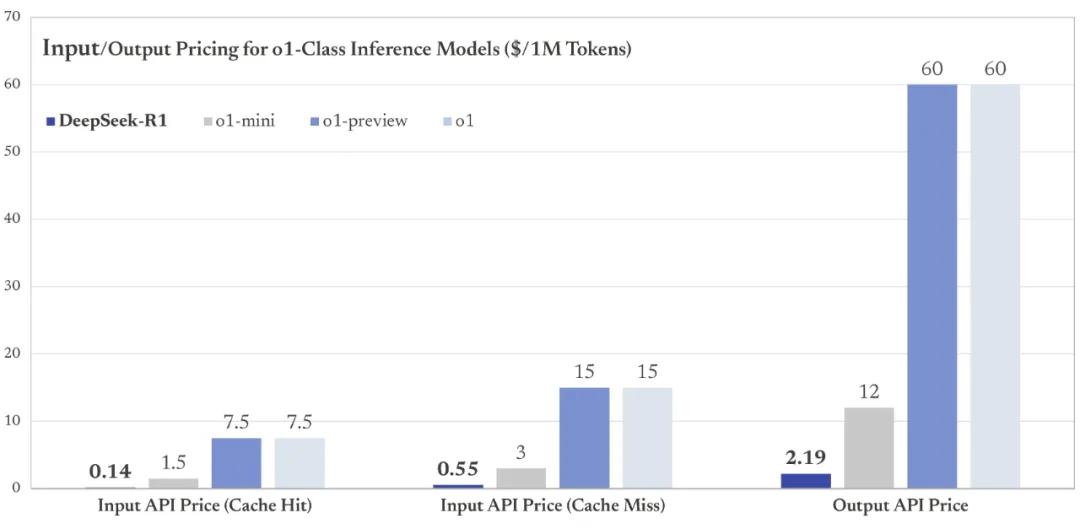
对比OpenAI o1 的 API 订价:每百万输入 tokens 15 好意思元、每百万输出 tokens 60 好意思元。
每百万输出订价,梗概仅为OpenAI的3.65%。
DeepSeek极高的性价比,险些是AI大模子界的拼多多。

DeepSeek还不竭开源到底,放出了背后的参谋论文。

DeepSeek-R1的推理才气蒸馏到较小的密集模子中,展示了较小模子也不错领有广宽的推理才气。
使用Qwen和Llama系列模子进行蒸馏,着力标明蒸馏后的模子在基准测试上推崇优异,举例DeepSeek-R1-Distill-Qwen-14B在AIME 2024上的通过率为69.7%。
Deepseek不会闭源,他们认为先有一个广宽的技能生态更繁重。MIT 授权:目田索要和贸易化!
英伟达的高等参谋科学家Jim Fan(范麟熙)对DeepSeek-R1的评价是:
咱们生计在这样一个期间:一家非好意思国公司正在让 OpenAI 的初志得以延续——简直洞开、为扫数东谈主赋能的前沿参谋。这绝不测旨。最真谛的着力才是最有可能的。

DeepSeek-R1 不仅开源了一系列模子,还公开了扫数查察窍门。它们可能是第一个展示 RL 飞轮要紧、捏续增长的 OSS 状貌。

梁文锋曾回来过,中国AI和好意思国AI的差距。
咱们看到的是中国AI不行能历久处在侍从的位置。咱们泛泛说中国AI和好意思国有一两年差距,但简直的gap是原创和师法之差。淌若这个不改变,中国历久只然而奴隶者,是以有些探索亦然逃不掉的。
简直的差距不是一年或两年,而是原创和师法之差。
转自:财经会议圈
 ]article_adlist-->
]article_adlist-->
(转自:中国地产基金百东谈主会)
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
干事剪辑:石秀珍 SF183开云(中国)Kaiyun·官方网站 - 登录入口